「電算機入門」履修者へ
授業内容の確認
1998.7.15
今日は最後であるが、これまでの回帰分析の説明の中でもれた大事な点について補足した。最初に、タイムラグを伴う回帰分析を説明した。たとえば、消費を所得で回帰する時に、同時期の所得が消費に影響を与えることはもちろんであるが、消費は習慣性の影響が大きく、今期のみならず、前期までの所得の習慣の影響を多く受けることになる。
Ct = a + b1 Yt + b2 Yt-1 + b3 Yt-2 .....
例を挙げれば、リストラ前の高い給与水準の影響がリストラ後の消費水準に影響を与えることは必至である。ただこうした分析の問題点は、説明変数の間で独立性が保てず多重共線性の問題が発生することである。
次に、非線型の関数の場合の回帰についてである。
例えば、Y = A K (1-a)L(a)
の場合についていえば、この両辺を対数変換すれば非線型が、次のような線形に変わる。
log Y = log A + (1-a)log K + a log L
そしてこの時重要な点はパラメーターが弾性値となることである。従って、1パーセントの変化がその変数の何パーセントの変化を生ずるかということが計測できる。
その後試験に移った。
授業全体に対する感想をBBSもしくはメールで送ること。
1998.7.8
これまで回帰分析の手法を学んできたが、授業としては今回が最後であるため、個々の回帰式で成立するマクロモデルについてその片鱗を垣間見ることにした。ここで取り上げたのはIS?LMモデルのうちのIS部分である。
Y=C+I+G+Ex-Im
C=C0+cYd (消費)
I=I0-br (投資)
G=G0 (政府消費)
Ex=Ex0 (輸出)
Im=Im0+mY (輸入)
Yd=Y-T (可処分所得)
T=T0+tY (税金)
ここで、消費関数は限界消費性向(c)、投資関数は利子率(r)、輸入関数は輸入性向(m)に依存することに注意。実際には以下のNEEDSのコードを使うこととする。
可処分所得 (YD)、国内総生産 (GDP)、民間消費 (CP)、政府最終消費(CG)、国内総固定資本形成(I)、在庫(J)、財サービスの輸出(E)、(控除)財サービスの輸入(MP)、全国銀行約定平均金利(RMAA)
ただし、投資はI+Jである。
最終的には、IS曲線は国内総生産(GDP)と利子率(全国約定平均金利、RMAA)との関係式となる。
来週の試験について
これまで学んだ中での大事なポイントを確認します。すべて持ち込み可。
1998.7.1
今回は、回帰分析のモデリングの際重要な原則を説明した。これまで説明した決定係数、t値以外に、
①説明変数の間では、互いに独立でなければならないこと。これが満たされないと、多重共線性の問題が発生する。事前にチェックするためには、相関表の中で、説明変数間の相関が小さいことを確認することが必要であり、大きい相関を示す場合は入れるべき説明変数を再検討すること。
②説明変数と残差の間にも独立性が要求されること。
③残差に、正あるいは負の相関があってはならないこと。ダービンワトソン比が2であることが望ましい。
④データがランダムな性質を示すミクロデータであるか、または安定的なマクロデータであるかによってパラメーターの正負が逆転する場合があるため、レベルによって取り入れるべき変数を考えること。
いずれにしても、正しい変数を取り入れないと真の値に大きな影響を与えてしまうことに注意。
宿題
投手の年俸に与える影響をネット上のデータを使って探ること。
1998.6.23
今回は、回帰分析の際の検定に入った。
実際の回帰分析は、母集団とサンプルとの関係の中で行うため、一度の回帰分析の結果をサンプルと考え、母集団における真のパラメーターを類推するわけである。そのためには、様々の検定方法があるが、今日はt値による考えを説明した。
t値 = パラメーター/標準誤差
であり、パラメーターの値が0である可能性をチェックする。
本来、回帰分析は、その性質上新しいデータ系列を加えると一般的には少しづつ決定係数は上昇してくる。しかしこれでは科学的とはいえず、そのモデルに加えるべきデータ系列を加えるべきである。
ここまで学んだ方法によって、より正しいモデリングを行うには、
まず、①相関表を作成して、ほとんど関係ないデータ系列についてはモデルに取り込まないこと、②t値が低いデータ系列を取り除くこと。
次に、ダミー変数について実例をもって説明した。例えば、戦争時と平和時の消費関数を考えるときや、大学卒、高校卒などの差に見られる質的データを回帰分析の中で取り込むためには、一般的にはダミー変数と呼ばれる0もしくは1の値を取る変数を使用する。
例えば、宿題でいえば、急行が止まるかどうか、バストイレが別かどうかなどをダミー変数で現わせばよい。
宿題
前回提示した家賃のモデルを完成させ、授業の感想に添付してメールで送ること。
1998.6.17
最初、前回理解の及ばなかった学生が多かったため、再度回帰分析の意義、回帰直線の導出の仕方、分散、回帰の周りの分散、決定係数の理解を進めた。
教科書の例で言えば、
| 家計 | 収入(X) | 消費(Y) |
|
1
|
20
|
16
|
|
2
|
29
|
26
|
|
3
|
32
|
25
|
|
4
|
35
|
23
|
|
5
|
23
|
19
|
|
6
|
35
|
31
|
|
7
|
32
|
30
|
|
8
|
30
|
26
|
|
9
|
43
|
36
|
|
10
|
21
|
18
|
| 平均 |
30
|
25
|
消費の分散=35.4
回帰の周りの分散=5.99
決定係数=(35.4 - 5.99)/ 35.4 = 0.831
Y = 0.961 + 0.8013 X
さらに、家族数という新しい情報を入れ、
| 家族数(Z) |
|
2
|
|
5
|
|
4
|
|
3
|
|
4
|
|
5
|
|
7
|
|
3
|
|
5
|
|
3
|
Y = - 0.5876 + 0.6458 X + 1.5159 Z
回帰の周りの分散 = 2.716
決定係数 = 0.923
となり、新しい情報を加えるたびに分散(平均的な誤りの程度)は減少し、つれて決定係数が1に近づくことがわかる。
その後、昨年行ったいくつかの回帰分析の具体例を示し、その重要性と有用性を理解した。
宿題
再来週までに、小田急線沿線の家賃相場を説明する回帰モデルを作ること。その際、家賃を説明する変数として、新宿からの距離(最寄りの駅の数)、部屋の大きさ、築年数、駅からの距離、急行停車駅であるかどうか、風呂とトイレが別であるかどうか、風呂の追炊きが出来るかどうか、ガスが使えるかどうか、などを入れること。資料としては、「週間賃貸住宅情報」などの生のデータを最低100件ほど、均等に集めること。
1998.6.10
今日から、回帰分析に入った。回帰分析は、経済学のみならず、すべての科学の分野で広く使われている基本的な分析方法である。これを理解するためには、統計学、数学が必要であるが、この授業では受講者の素養を考え、出来るだけ易しくし、特に大事なポイントに的を絞って説明したい。最初に、基本統計値の説明から入った。
分散
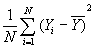
すなわち、個々のデータから平均を引いた偏差の二乗の和の平均である。これは、分布の散らばり方を表現する。
標準偏差
![]()
これらの基本統計値の理解のために、いわゆる偏差値を計算してみた。
偏差値 =  ,
k=10 (10の場合が多い)
,
k=10 (10の場合が多い)
この後、所得と消費のデータを基に、散布図を書く。そこでは右上がりの関係、すなわち所得が増えれば消費が増えるという関係が読み取れる。そこで、こうしたデータ群を代表するにふさわしい直線を科学的に引く方法が、回帰分析である。その方法としては、個々のデータからその直線上におろした距離(直線では現わしきれない誤差ともいえるもの)の二乗の和(S)を最小にすることとする。
S = 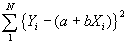
この回帰直線の係数bは、いわゆる限界消費性向に当たり、これにより様々な経済政策上の提言が行われうるのであり、また、新たなFact Findingの有力な手段となる。
Excel上の回帰分析ツールを使い、これらの係数を求める。そこで得られる様々な統計値のうちで、決定係数について説明した。

これが意味するところは、情報のない場合の誤差が、所得という新しい情報が入ったときにどの程度減少するかを現わしたものである。これらのことは、なかなか一度では理解しにくいようなので、再度次週に説明することとする。
宿題
先週、十分に出来ていなかったGDPのグラフを打ち出し、そこに出来るだけ詳しい経済事象を書き込み、提出すること。
1998.6.3
最初に、専修大学経済学部の2年から3年に進級する時点における留年率の高さ(14%)を分析し、それが1年次にほとんど学校から離れてしまうことによるものであることを説明した。その原因は、①大学に入ることが目的であったため、入ってからの目標を失った、②高校とは違う各自の自主的な勉学態度が理解されていない、③遊び、アルバイト、サークル活動にのめり込んでしまった、④授業がつまらなく感じた、⑥希望大学、学部でなかった、⑦長い坂を敬遠するなどであろう。米国の例では、このようなケースでは退学になるのが一般的である。なぜならば、卒業要件は単位数だけでなく、成績も多いに関係するからである。例え単位を取得しても、平均して「良」を維持しないと退学になる。一つの「不可」は一つの「優」でカバーしなければならず、しかもその「優」は、日本とは違い、トップ10%程度にしか与えられない。こうして考えてみると、米国の基準に沿えば、おそらく半分以上の専修の学生は1年以内に退学になってしまうであろう。留年はそれによって、そのまま退学する人もいるなどその後の大学生活、就職に大きく影響するものである。
本題に入って、宿題を検討した。
実質GDPの各要素を日経NEEDSから取り込み以下の計算を行った。
前年比残念ながら、提出された宿題の中で、正しく寄与度まで計算できた人は、わずかであった。構成比
寄与度
次に、ケインズの投資乗数の概念を表計算で確認することを行った。
投資の純増加分は、その1/s倍だけの所得増加を生ずるが(△ Y= 1/s △ I、あるいは△ Y= 1/(1-c) △ Iここで、sは限界貯蓄性向、cは限界消費性向)、それを確認するために次のような例を考えた。
△ 50 = 1/0.2 * △ 10最初の投資増10がまず、所得増になり、その80%が消費増になる。それが、再び所得増になる過程を繰り返し計算し、波及効果を合計すると、ほぼ50になる。
問題は、発展途上国のケースのように、この無限回繰り返す過程が、早い段階で消滅することが多く、そのための市場、経済システムの整備が必要となる。
その後、恒久減税の効果を見るために、税を取り入れた次のモデルを考えた。
Yd = (1-t)* Y、Ydは可処分所得
Y= 1/(1-c) *(1-t)△ Iこれらのモデルを使えば、公共投資の増加(△ Iの増加)、恒久減税(tの低下)、消費の促進(cの上昇)の所得増の効果が測定可能となる。
宿題
実質GDPデータの対前年比のグラフ上に、主要な経済事象を図形ツールを使って書き込み、私あてにメールで送付すること。授業の感想をBBSに載せること。
1998.5.27
今日から、実際の経済分析に入るが、その前に勉強の姿勢について述べた。
掲載されているプロフィールを読むと、高校時代に体を動かして部活に燃えていた人が多く見られるが、大学に入るとそうした充実感に乏しいと感ずる人が大半であることがわかる。高校における部活では、体を動かすというわかりやすく、比較的容易に充実しやすいものであったが、大学では知的なものに関心を持ち、論理的な分析を行い、頭で汗をかくことの喜びを味わって欲しい。これはそれほど簡単ではない。
そのためには、自分を縛る「自分の好き嫌い」だけで、短絡的に物事を判断し、自分が関心あるものにしか関心を持たないという姿勢を考え直すことが必要である。自分の世界を広げ、多くの出来事、人々に関心を持つことが知的な充実の始まりである。
今日のテーマ
GDPおよび、その構成要素のデータを取り出し、前年比、寄与度を計算し、グラフ化する。
最初に、経済企画庁発表の以下の文章を読んだ。
平成8年度国民経済計算のポイント
平成9年12月16日
経済研究所
1.経済成長率
(名目成長率は2.8%の増加)
平成8年度の国内総生産(=GDP)は、名目で前年度比2.8%増加し、503兆円となった。
(実質成長率は3.2%増、3年連続の名実逆転)
実質経済成長率は、8年度3.2%増(7年度2.8%増)と伸びを強め、平成2年度(同5.5%増)以来6年ぶりの高い伸び
となった。内外需別の寄与度をみると、内需の寄与度は+3.5%、財貨・サービスの純輸出(外需)の寄与度は△0.4%であっ
た。また、実質の伸びが名目の伸びを上回った結果、3年連続して名実逆転となった。
(デフレーターは3年連続して下落)
GDPデフレーターは、6年度△0.2%、7年度△0.6%の後、8年度には△0.3%となり、3年連続して下落した。
この文章に出てくる、成長率、名目、実質、デフレーター、寄与度の意味を理解するために実際にGDPの構成要素を検討した。
GDP=民間最終消費+政府最終消費+総固定資本形成+在庫増加+財、サービスの輸出-財、サービスの輸入
大型コンピューターから、データを取り込み上の式が正しいことを確認。
実質=名目/デフレーター、
伸び率=(本年ー前年)/前年*100
寄与度=前年の構成比*伸び率
の関係を理解した上で、GDPのデータを加工処理し、グラフ化を行った。
次に、授業中の例を挙げて、寄与度計算を再説しよう。
消費の寄与度10%は、前年比14.3%*構成比(昨年)0.7
10 = 14.3 * 0.7
同じように、投資の寄与度10%は、前年比33.3%*構成比(昨年)0.3
10 = 33.3 * 0.3
合計の伸び率20% = 消費の寄与度10% + 投資の寄与度10%
ここで注意したいことは、前年比の計算では、相対位置指定で良いが、構成比の計算では列は絶対番地指定となる。
| 消費 | 投資 | 合計 | |
| 昨年 |
70
|
30
|
100
|
| 今年 |
80
|
40
|
120
|
| 前年比 | |||
| 消費 | 投資 | 合計 | |
| 昨年 | |||
| 今年 |
14.3
|
33.3
|
20.0
|
| 構成比 | |||
| 消費 | 投資 | 合計 | |
| 昨年 |
0.700
|
0.300
|
1.000
|
| 今年 |
0.667
|
0.333
|
1.000
|
| 寄与度 | |||
| 消費 | 投資 | 合計 | |
| 昨年 | |||
| 今年 |
10.0
|
10.0
|
20.0
|
名目GDPの対前年比伸び率、寄与度を計算し、メールで送ること。
今日の授業の感想をBBSに載せること。
1998.5.20
最初に、来年度の就職状況について、実際に活動中の4年生から得た情報を説明した。労働市場がタイトになる中で、企業は良い人材をじっくり選別する態度をとっている。名の知れた企業では平均10倍から100倍程度の競争があり、何回かの面接を経てほんのわずかな人数を採用する。1次面接では、サークルだけしかしてきていない学生も何とかとおることが出来ても、その後の面接で勉学面で聞かれると、マニュアルどおりの答えでは、成功しない。答えられる中身がないと説得できるものではない。自分の表現力、論理的な分析、応答姿勢が見られる。
今日の授業の目的は、データの収集方法である。最初に、次の3つのインターネットのサイトからデータを取り込んだ。
http://www.stat.go.jp (総理府統計局)
http://www.epa.go.jp (経済企画庁)
http://www.boj.or.jp (日本銀行)
これらのサイトでは、エクセルのフォーマットでデータが提供されていることが多い。
次に、大型コンピューターとの間の捜査方法と概念を説明後、日経NEEDSデータへのアクセスを試みた。
取り込方をここにもう一度説明する。
①Communinetの中のM680Hを起動させる。user idとpasswordを入力。
②>>が出たら、NEEDS と入力しenter keyを押す(テンキーの右のキー)
③以下、メニュー形式を選択し、目的のデータまでたどり着く。
④データの形式、データの始まりと終わりの時期を確認する。
⑤選びたいデータを”S”と入力して、指定する。
⑥enterを押す。
⑦データの取り込み画面で、MSDOS形式のフロッピー、データの種類(月、四半期、年など)、データの始まりと終わりの時期を指定する。
⑧enterを押すと、@HENKAN.DATAにデータが保存されたと表示される。
⑨このプログラムを一度終了し、再度M680Hを起動させる。user idとpasswordを入力。
⑩>>が出たら、IFITと入力。
⑪Host->Terminal(1)、データ名として、@HENKAN.DATA、フロッピーのファイル名として、A:¥DATA(ここは好きな名前を入力)
⑫enterを押すと、データが大型コンピュータから、フロッピーに転送され、transmissionの完了通知が出る。
⑬Excelを起動し、フロッピー上のファイル(ここでは”DATA”)を開く。そのさい、ウイザードの中で、カンマ区切りを指定する。
宿題
景気動向指数の、先行、一致、遅行系列をエクセルに取り込み、授業の感想とともに私にメールで送ること。
1998.5.13
最初に、宿題の答えを解説した後で、今日の2コマで、表計算ソフトの大方の説明を行う旨を述べた。そのため、スピードは速くなるが、教科書にそったものであり、後で復習が必要であること、そして、これからの授業の中で、実際に何度も繰り返し行うので、心配ないことを説明した。
主な作業
①1994年から1997年の首都圏の大学の志願者数の推移の表を作成
②合計を計算する中で、式のあらわし方、関数の使い方(ここではsum, average)を学ぶ
③データのグラフ化、棒グラフ、円グラフ、これに関連して、オブジェクトのコンセプトを説明
④ワープロへエクセルのデータを転送、貼り付ける作業
⑤売上高の表を作成して、相対番地、絶対番地、さらにIF関数の説明
⑥これらの他、パーセンテージ、3桁ごとの区切り、表上の表現と内容ボックスとの違いなど。
宿題
①教科書の合否判定の例題を解き、メールで送ること
②授業の感想を載せること
1998.5.6
最初に、インターネットによる海外へのアクセスを試みた。そのための、yahooによるサイト検索を試みた。
①whitehouseのサイトに行き、最新の報道発表(press release)を読む。(www.whitehouse.gov)
②ハーバード大学に行き、経済学部のコース一覧の中で、国際経済の講義を探す。(www.harvard.edu)
③通信政策に関する資料を一つ探す。(governmentのセクションから)
④スタンフォード大学の、経済学部のコース資料を探す。(www.stanford.edu)
多くの学生が、英語力の不足のため、十分にサイトを探せなかった。ネット上の情報のおそらく9割以上は英語であると考えられるので、日常的に英語力のアップを図りながら、果敢にチャレンジして欲しい。また、ネットを使うことで、自然に慣れてくるという効果も期待できよう。
次に、表計算言語の説明を行った。
簡単に、表計算の歴史を得なかで、世界最初の表計算言語「visicalc」と日本最初の表計算言語「PIPS」についてそのいきさつを説明。PIPSについては、私が日本銀行にいたころに自分の業務をより円滑にすべく自分のために開発したものであり、その基本的な考えは以下の通りである。
①多くの「仕事」は「表」で表現できること。
多くのデータ処理の「仕事」は、「表」から「表」を作り出すこと。
従って、「表」の様々な加工処理が出来れば、それはすなわち、「仕事」をしたことになること。
②それまでの、BASIC,FORTRAN,COBOLなどの高級言語と呼ばれる言語を使って仕事のためにプログラムを作ることは、プログラムに対する適性から見ても一般的には難しいこと。
③高級言語の、命令語レベルは日常の思考レベルから見て、計算機よりであり、知的レベルに比べるとかなりの差がある。このため、PIPSでは日常的な知的レベルで命令語をつくりあげた。
開発の経緯や、より詳しい内容、当時のパーソナルコンピューターの状況などについては、「PIPS誕生記」(日経「サイエンス」、1982)などを参照して欲しい。(なお、これらについて、現時点から見た評価も合わせた形で、本の形で公表したいと考えている)
表計算言語の基本的な考えを説明後、すぐにEXCELをたちあげ、実際に簡単な例を試みた。
以下は、宿題となった。
身長が140cmから200cmまでの人の、標準体重を計算し、その結果を私あてのメールに添付すること。
標準体重の式は、(身長ー100)*0.9である。
1998.4.22
現在の日本が直面している課題は多いが、この授業で関連するものに「情報化」、「国際化」の後れがある。情報化については、先進国の中で情報処理教育は際立って遅れている。文部省は中学校、高等学校におけるコンピュータの設置を義務づけたが、実際には大学入試の科目になっていないため履修する学生は少ない。そのため、大学入学時においては先進国の学生と比べて大きな差が出ている。また、国際化については、一つの目安である英語力でみても、この数年は低下を示すデータが現れている。(例えば、TOEFLのスコアはこのところ毎年低下し、今やアジアの中でも下位に位置している)
この授業では、情報化はもちろんのこと、国際化の遅れについても関心を持ってほしい。そのために、一つのツールとして、インターネットを利用したいと考えている。実際、国際化の点で言えば、ネット上の情報の大半は英語によるため、日頃から積極的に海外のネットにアクセスして欲しい。
授業におけるコミュニケーションを早くとりたいため、少し駆け足であったがインターネットの設定を行い、実際に最初のメールを送付した。一部送付できない人がいたが、そのほとんどが設定のミスであった。
netscape navigatorのメール設定(主要ポイント)
①メールのフォルダーの作成と設定
h:\ユーザーID\netscape\mail
②optionのmail & preferencesの設定
smtp server : smtp.isc.senshu-u.ac.jp
pop server : pop3.isc.senshu-u.ac.jp
Identity の設定
---Email address : ユーザーID@isc.senshu-u.ac.jp
設定後、宿題でFDに保存しておいたファイル(先週の項を参考)をメールに添付して私あてに送付した。これについては、各自のプロフィールとして掲載。
宿題
- まだ、プロフィールを送付していない人は、メールを送付すること。
- 各自の写真を掲載するため、ネットに載せて欲しい写真を持ってくること。
- 授業用のBBSに、授業の感想を載せること。
最初に、授業履修者の確定をした。先に選ばれた57名の中で、最初の授業に現れなかった13人に変えて、キャンセル待ちなどの希望者の履修を認めた。次に、この授業について、その目的を大学での勉強との関係で説明をした。以下は、その概略である。
まず、この授業は受け身で聞く授業ではなく、本人の積極的な参加が必要とされる。授業以外での予習、復習に時間を取ってほしい。(昨年は平均2時間前後)私としてはゼミと同様の気持ちで、できるだけ個々人とのコミュニケーションをとっていきたいと考えている。そのためのツールとして、インターネットを大いに活用する。EメールあるいはBBS(掲示板)により、学生同士、また学生と私との間の意志疎通を行なっていきたい。また、インターネット上で、毎回の授業の中身、授業の感想、授業評価など授業の情報を開示する。この情報開示という点については、現在日本経済が抱える裁量主義、意志決定過程の不明瞭性に対する一つの実験であり、昨年来インターネットの利用によってゼミ、授業活動が多いに活性化していることを踏まえ、今年度は更にこれを進めるものである。
単位を取るという視点から見ると、この授業はやるべき内容が多岐にわたり宿題も多く努力を要するため、投入するコストと成果(単位取得)という関係から見れば効率の最も悪いものの一つであろう。しかし、大学生活の中で充実した時間を授業で得るという目的からは、恐らくゼミに匹敵するものとなるものと考えている。その意味で、より高い目的を設定し、大学生活をより充実したものにすることが必要で、この授業はそのための一つのチャンスを提供したいと考える。(より高い目的を持てることがその人の能力の高さを表すとも考えられよう。)
なお、本年度は私が後半短期在外研究で日本を離れるため、前期集中となるが、そのため例年1年かけたことを半年でこなさねばならず、その分学生諸君の積極的な姿勢が要求されるものである。その意味から、全回出席が前提であり、無断欠席を続けると原則として単位を認定しないこととする。
以下は授業の要点
① コンピューターのシステムの起動方法
② ハードウエアの概略説明。
Keyboard, mouse, CPU, FD, RAM, Hard Diskなどの説明。
③ 3桁ごとに区切る数字の読み方の説明。thousand, million,
billionにK, Mega, Gigaが対応していること。
④ FDの初期化とデータの保存法
⑤ 日本語のかな漢字変換の基本説明(配布資料)
⑥ Netscape Navigatorの起動と、私のホームページへのアクセス方法
なお、授業の内容確認、宿題、お知らせなどをこのように毎回載せるので、できるだけ頻繁にホームページへアクセスすること。
来週までの宿題
① 高校時代の思い出
② 興味のあること、あるいは趣味
③ 現在の大学生活について
④ この授業への期待
⑤ 将来の職業について
この5点を書き、FDへ保存しておくこと。来週は、そのデータをインターネット上に載せることとする。